I’ve never really touched rake before, but since switching to Jekyll I’m finding that it’s becoming an essential part of my workflow. In the limited area of blogging, at least. rake is a version of make in which you define all your targets in Ruby. Because practically anything would be an improvement over Makefile syntax, …
Monthly Archives: October 2011
XSS is fun!
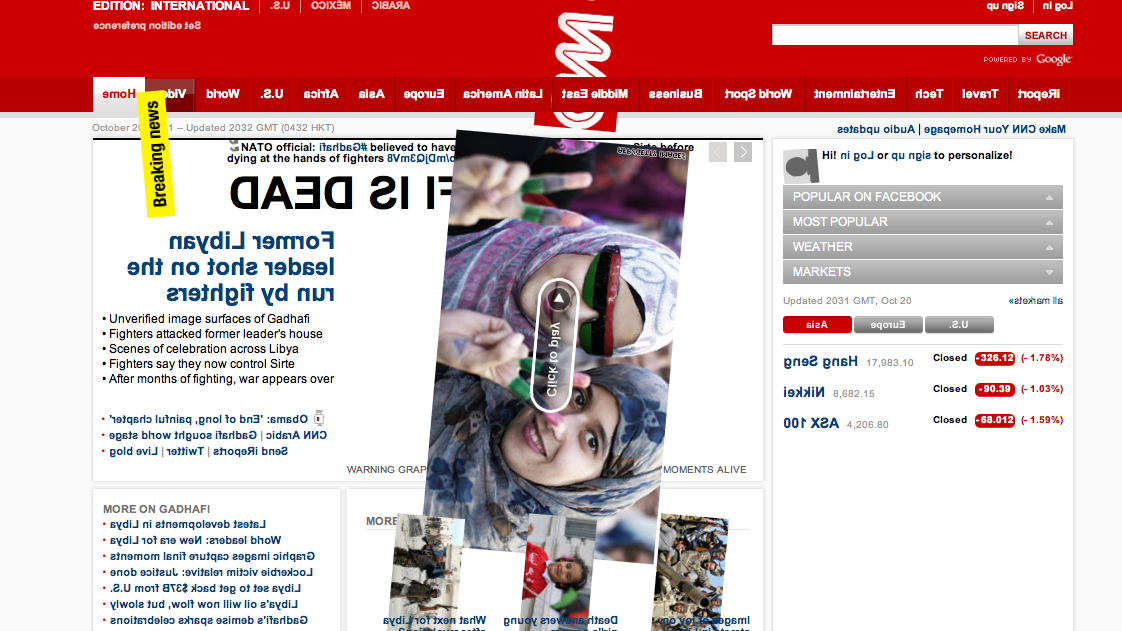
Pretending innocence, I ask why all these high profile websites have their homepages covered in spinning images? CNN (screenshot) The New York Times (screenshot) Mashable (screenshot) Fox News (screenshot) Okay, obviously enough, I’m messing with them. But how can I do that? The answer is cross site scripting (“XSS”). XSS is surprisingly common, and nigh-universally …
Jekyll
I’ve just redone my website using Jekyll. It is now completely static. No PHP, no database, nothing like that. Why did I do this? It’s quite soothing knowing that all my content is version controlled. I am now nigh-immune to traffic spikes. I was using caching with WordPress before, so it had never been an …
To replace PHP you need
(Expanding slightly on my response to this HN thread.) First: to be on all shared hosting everywhere. I.e. you need to be really easy to install, and preferably not involve long-running processes that shared hosts might choke on. Second: to be beginner friendly. No requirement of understanding MVC, or running commands in a shell (hi …
Inane, random, and opinionated
I need to bear in mind that the threshold for the Hacker News front page is a bit lower late at night on Friday, and perhaps only submit my less inane, random, and opinionated stuff in that timeframe. Oh, who am I kidding? It’s great for getting views.